Securing AI pipelines against data poisoning: a practical guide for technical teams
Data poisoning is one of the more practical risks in AI security because it targets the pipeline rather than the model alone. If an attacker, careless user, or unreliable upstream process can influence training data, labelling, feedback, or retraining inputs, they may be able to degrade model performance, bias outputs, or introduce hidden behaviours that only appear under certain conditions. For UK SMEs adopting AI in products, internal automation, or decision support, the issue is not just model accuracy. It is trust in the data supply chain that feeds the model.
This matters because many AI systems are built from multiple moving parts: data sources, feature stores, training jobs, evaluation sets, model registries, deployment pipelines, and feedback loops. Each handoff creates a trust boundary. If those boundaries are not explicit, poisoning can enter through the least obvious route, such as a third-party dataset, a human review queue, or user-generated feedback that is later recycled into training.
Why data poisoning matters in AI pipelines
In a conventional application, an attacker usually tries to alter code, credentials, or infrastructure. In an AI pipeline, the target may be the data itself. Poisoned data can be used to reduce model quality, create systematic blind spots, or embed backdoors that are difficult to detect during normal testing. The impact depends on the use case. A recommendation engine may become unreliable. A fraud model may miss specific patterns. A support assistant may learn unsafe or misleading associations.
Where poisoning can enter the pipeline
Common entry points include raw data ingestion, label generation, feature engineering, synthetic data generation, data augmentation, manual review, and continuous retraining. Even if the core training set is well controlled, downstream feedback can still contaminate future versions. For example, if analysts override labels without traceability, or if customer feedback is automatically folded into retraining, the pipeline can gradually absorb bad data.
How poisoning differs from prompt injection and model abuse
Prompt injection and model abuse target the runtime behaviour of a model, usually by manipulating prompts, tools, or context. Data poisoning targets the training or fine-tuning lifecycle. The distinction matters because the controls are different. Prompt injection is handled with input filtering, tool isolation, and output constraints. Data poisoning is handled with provenance, curation, validation, versioning, and release gates. In practice, mature AI security programmes need both.
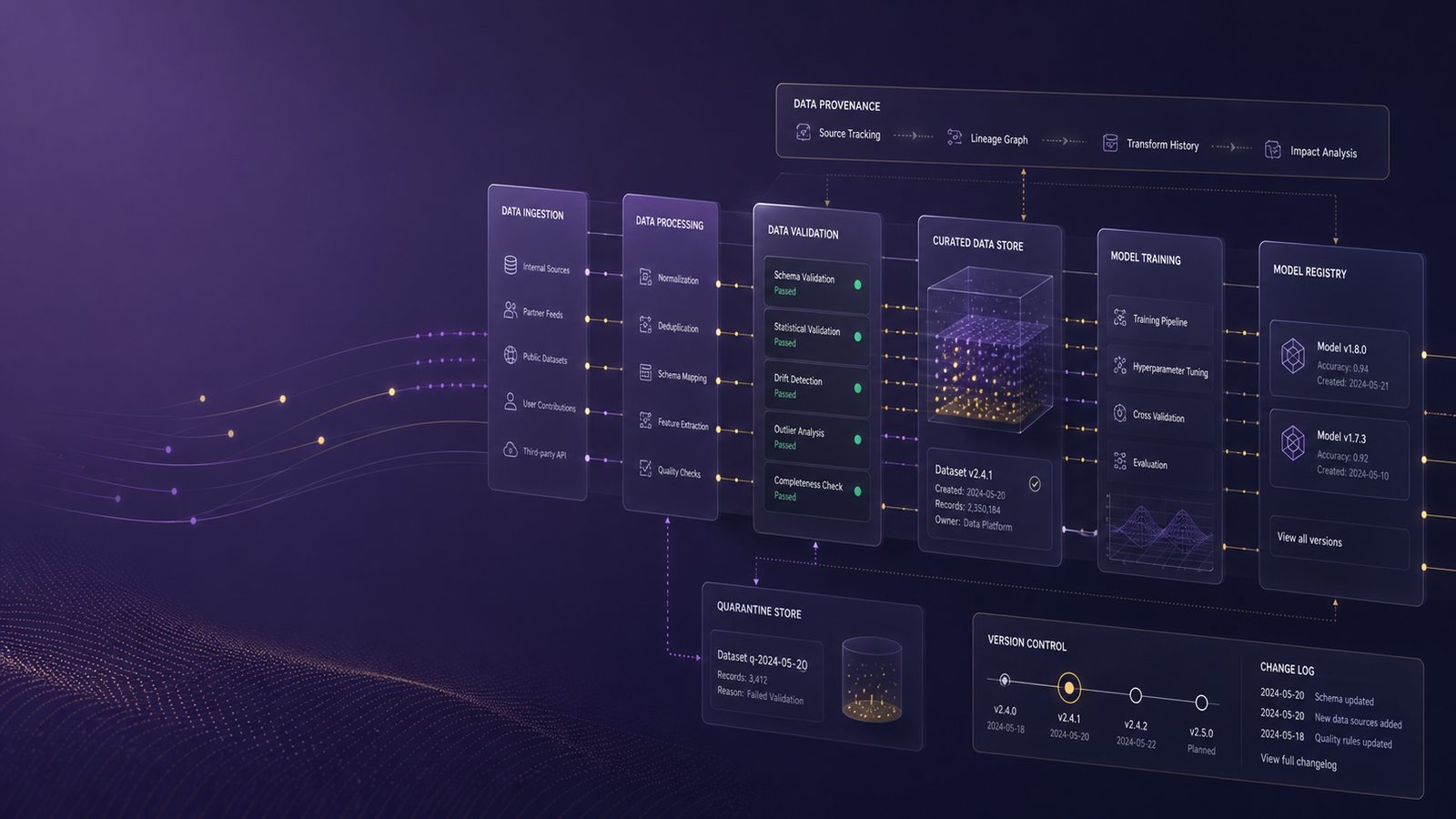
Map the pipeline and identify trust boundaries
Before adding controls, map the full data path from source to production. A simple architecture diagram is often enough to start, but it should show where data is collected, transformed, labelled, stored, trained, evaluated, and promoted. Include any manual steps, because human review queues are often overlooked trust boundaries.
Data sources, feature stores, training jobs, and model registries
For each stage, record the owner, the source of truth, the storage location, and the access model. A feature store may be populated from internal systems, partner feeds, or public data. Training jobs may pull from object storage, a warehouse, or a snapshot in a data lake. Model registries should record which dataset versions, code commits, and environment settings produced a given model artefact. If you cannot answer those questions quickly, your lineage is too weak to support reliable incident response.
In technical terms, treat each stage as a separate control plane. Ingestion controls should not be assumed to protect training. Training controls should not be assumed to protect promotion. Promotion controls should not be assumed to protect online feedback. This separation helps you define where to apply RBAC, approval workflows, integrity checks, and logging.
Applying threat modelling with STRIDE and attack surface review
STRIDE is useful here because it forces a structured review of spoofing, tampering, repudiation, information disclosure, denial of service, and elevation of privilege across the pipeline. For poisoning, tampering is the obvious category, but spoofing and repudiation are also relevant. An attacker may impersonate a trusted source, or a legitimate user may deny having submitted malicious feedback if the pipeline lacks auditability.
Pair STRIDE with an attack surface review. Ask where untrusted input enters, where it is transformed, where it is cached, and where it is reused. Pay particular attention to automated joins between datasets, scheduled retraining jobs, and any process that promotes data from a low-trust zone into a high-trust one. If your team already uses data flow diagrams, extend them with trust labels and data quality checks.
Common poisoning patterns to design against
Poisoning is not a single technique. It usually appears as a pattern of manipulation that is designed to blend in with normal data. The controls you choose should reflect the pattern you are most likely to face.
Label manipulation, sample injection, and backdoored training data
Label manipulation changes the ground truth. Sample injection adds malicious or misleading records to skew the training distribution. Backdoored training data is crafted so the model behaves normally in most cases but responds in a specific way when a trigger is present. These patterns are especially relevant where data can be contributed by external parties, crowdsourced reviewers, or semi-trusted internal teams.
Defensive design should assume that not every record is equally trustworthy. Weight data by source confidence, isolate high-risk sources, and avoid mixing unverified data directly into gold-standard training sets. Where possible, keep a clean reference dataset that is tightly controlled and used for regression testing.
Contamination in synthetic data, feedback loops, and human review queues
Synthetic data can be useful, but it can also amplify errors if the generation process is fed by biased or poisoned inputs. Feedback loops are another common problem. If model outputs are used to create future labels, mistakes can become self-reinforcing. Human review queues can also be abused if reviewers are rushed, under-trained, or unable to see the original source context.
For SMEs, the practical lesson is to avoid blind automation in the curation stage. Keep a human in the loop for high-impact changes, but make sure the human has enough context to make a meaningful decision. A reviewer who only sees a label and not the source lineage is not really validating the data.
Build controls into data ingestion and curation
The strongest place to stop poisoning is before contaminated data reaches training. That means building controls into ingestion, normalisation, and curation rather than relying on model-side detection alone.
Source allowlisting, schema validation, and provenance checks
Start with source allowlisting. Only accept data from known systems, signed feeds, or approved partners. Enforce schema validation at the ingestion boundary so malformed or unexpected fields are rejected early. For structured data, use strict type checking and range validation. For unstructured data, apply file-type restrictions, size limits, and content scanning.
Provenance checks are equally important. Record where the data came from, when it was collected, who or what submitted it, and which transformation steps were applied. A simple pattern is to attach immutable metadata to each dataset shard or object, then propagate that metadata through the pipeline. If you use object storage, object tags or sidecar manifests can help. If you use a data platform, lineage features should be enabled by default rather than treated as optional.
Where data is sourced from external APIs or partners, use service-to-service authentication, TLS, and least-privilege credentials. Limit the blast radius of any one feed by isolating it in its own landing zone before it is merged with higher-trust data.
Deduplication, anomaly detection, and quarantine workflows
Deduplication reduces the chance that repeated samples distort the training distribution. It also helps catch replayed records or bulk injections. Anomaly detection should be applied to both content and metadata. Look for unusual volume, timing, label distribution, source concentration, or feature drift. A sudden spike in one class, a new source domain, or a cluster of near-identical records can all be warning signs.
Do not let suspicious data flow straight into training. Quarantine it. A quarantine workflow should hold the data in a separate location, assign an owner, and require review before release. This is a simple control, but it is often missing because teams assume data quality checks are enough. They are not. Checks can flag a problem, but quarantine prevents immediate contamination.
Harden training and evaluation workflows
Once data reaches training, your goal is to make the process reproducible and resistant to silent tampering. If a model changes unexpectedly, you need to know whether the cause was code, configuration, data, or environment drift.
Dataset versioning, signed artefacts, and reproducible training runs
Version every dataset used for training and evaluation. Treat datasets as artefacts with lifecycle management, not as disposable files. Store hashes, timestamps, source references, and transformation history. If possible, sign critical artefacts and verify signatures before use. This is especially useful where training is automated through CI/CD or MLOps pipelines.
Reproducible training runs should pin code, dependencies, container images, and dataset versions. A model registry should record the exact inputs that produced each model. Tools such as MLflow, DVC, or equivalent platform features can support this pattern, but the important point is the discipline, not the product. If a retrain cannot be reproduced, it is much harder to investigate whether poisoning played a role.
Robust validation, holdout design, and canary evaluation
Validation should not rely on a single random split. Use a holdout set that is protected from routine pipeline access and kept separate from training feedback. For high-risk use cases, maintain a challenge set that contains edge cases, rare classes, and known failure modes. This helps detect whether a new training run has degraded performance in a targeted way.
Canary evaluation is also useful. Before promoting a model broadly, run it against a limited slice of traffic or a controlled internal workload. Compare its behaviour with the previous version and watch for unexpected shifts in precision, recall, calibration, or class-specific error rates. A poisoned model may still look acceptable on aggregate metrics while failing in a narrow but important segment.
Detect poisoning attempts with monitoring and telemetry
Detection is not a substitute for prevention, but it is essential because some poisoning attempts will get through. Monitoring should focus on the data pipeline as much as the model runtime.
Drift, outlier, and label-quality signals in ML observability
Monitor feature drift, label drift, class balance, missingness, and outlier rates. Sudden changes in any of these can indicate contamination, upstream process failure, or a genuine business shift. The difference matters, so alerting should be paired with context such as source changes, release events, or campaign activity.
Label quality deserves special attention. If labels are generated by humans, measure inter-rater agreement, override rates, and review latency. If labels are inferred from downstream events, check for feedback delays and missing confirmations. A drop in label quality can be the first sign that the training set is no longer trustworthy.
Logging for data lineage, model changes, and human overrides
Log enough to reconstruct the path of a dataset through the pipeline. At minimum, capture source identifiers, transformation steps, validation outcomes, quarantine decisions, training job IDs, model version IDs, and promotion approvals. Human overrides should be logged with who approved them, what was changed, and why. This is valuable both for incident response and for routine governance.
Feed these logs into your SIEM if they are operationally important. Correlating data pipeline events with infrastructure and identity logs can help distinguish a poisoning attempt from a simple data quality issue. For example, a spike in rejected records combined with a new service principal or an unusual access pattern may indicate a broader compromise.
Protect the model release and feedback loop
Many teams focus on training and then forget that the release process can reintroduce risk. A clean model can still be undermined by a weak promotion process or an unsafe feedback loop.
Approval gates for retraining and promotion
Use approval gates for retraining, model promotion, and rollback. The gate should require evidence that the new model was trained on approved dataset versions, passed defined tests, and did not introduce unacceptable regressions. Keep the approval criteria simple and measurable. If the criteria are vague, they will be bypassed under delivery pressure.
For SMEs, a lightweight change control process is usually enough. The aim is not bureaucracy. It is to ensure that a model does not move from experimentation to production without a traceable decision. If you already use change management for infrastructure or application releases, extend the same discipline to model artefacts and datasets.
Safeguards for online learning and user-generated feedback
Online learning and continuous feedback loops are attractive because they promise faster adaptation, but they also widen the poisoning surface. If you use user-generated feedback, separate it from immediate retraining. Score it, sample it, and review it before it influences the next model version. Apply rate limits and abuse detection to feedback channels, especially where anonymous or low-friction submission is allowed.
Where possible, use delayed retraining rather than live updates. This gives you time to inspect the data, compare it with historical patterns, and reject suspicious clusters. If the business requires near-real-time adaptation, keep the update window narrow and the rollback path simple.
Operationalise response when poisoning is suspected
If you suspect poisoning, the response should be focused on containment, evidence preservation, and safe recovery. The first question is not how to fix the model. It is how to stop further contamination.
Triage, rollback, and dataset containment
Start by identifying the affected model versions, dataset versions, and pipelines. Freeze retraining jobs and isolate the suspect data sources. If a recent model version appears compromised, roll back to the last known good artefact while you investigate. Preserve the evidence needed to understand the scope of the issue, including lineage records, logs, and approval history.
Containment may also involve disabling feedback ingestion, pausing automated labelling, or blocking a specific source feed. If the pipeline is multi-tenant or shared across teams, make sure the containment action does not create a wider outage than necessary. A good runbook should define who can pause training, who can approve rollback, and how the business is informed.
Lessons learned, control tuning, and governance updates
After recovery, review how the contaminated data entered the pipeline and which control failed to stop it. Update allowlists, validation rules, anomaly thresholds, and approval gates accordingly. If the issue exposed a gap in ownership, fix that too. Many AI incidents are really governance failures disguised as technical ones.
For UK SMEs, it is sensible to align this work with broader information security management practices. An ISO 27001-aligned ISMS can help you keep ownership, risk treatment, evidence, and review cycles consistent across AI and non-AI systems. The value is in the discipline of managing risk, not in treating AI as a special case that sits outside normal controls.
Practical starting point for technical teams
If you want a manageable first step, focus on four things: map the pipeline, version the data, quarantine suspicious inputs, and add promotion gates. Those controls will not eliminate all poisoning risk, but they will materially improve your ability to detect, contain, and recover from it.
From there, build out lineage logging, drift monitoring, and feedback safeguards. The aim is to make poisoning harder to introduce, easier to spot, and less likely to reach production unnoticed. That is a realistic security outcome for most SMEs, and usually a better investment than trying to build a perfect model-side defence.
If you would like help aligning AI pipeline controls with a broader risk-based security programme, including an ISO 27001-aligned approach to governance and evidence, speak to a consultant.
FAQ
How is data poisoning different from prompt injection in AI systems? Data poisoning targets the training or retraining pipeline by contaminating the data used to build the model. Prompt injection targets runtime behaviour by manipulating the input given to a model or its tools. They require different controls, although both should be considered in a complete AI threat model.
What are the most effective controls for preventing poisoned data from entering an ML pipeline? The most effective controls are source allowlisting, schema validation, provenance tracking, dataset versioning, quarantine workflows, and approval gates for retraining and promotion. Monitoring for drift, outliers, and label quality adds a second layer of defence when prevention is not enough.
Should SMEs use synthetic data to reduce poisoning risk? Synthetic data can help in some cases, but it is not a substitute for trusted source data. If the generation process is fed by poor-quality or poisoned inputs, the synthetic output can inherit those problems. Use it carefully, with validation and clear separation from gold-standard datasets.
What should be logged for AI pipeline investigations? Log source identifiers, transformation steps, validation results, quarantine decisions, dataset hashes, training job IDs, model version IDs, and human approvals or overrides. This gives you enough lineage to reconstruct what happened if a model behaves unexpectedly.
Comments are closed